|
The CUBE Lab focuses broadly on multi-modal methods for computer vision, digital humans, and computational behavior science, specifically in areas of modelling, analysis, and synthesis of human behavior and environment using diverse sensors. |
|
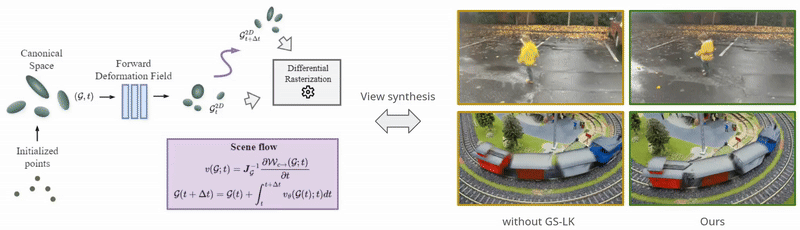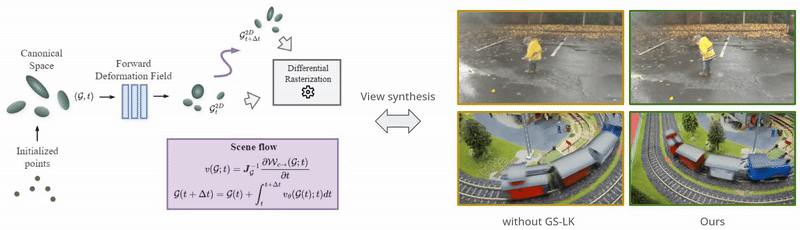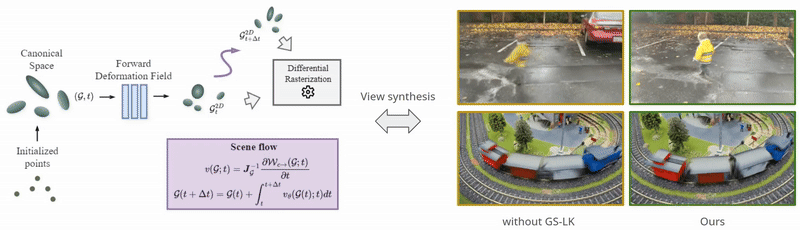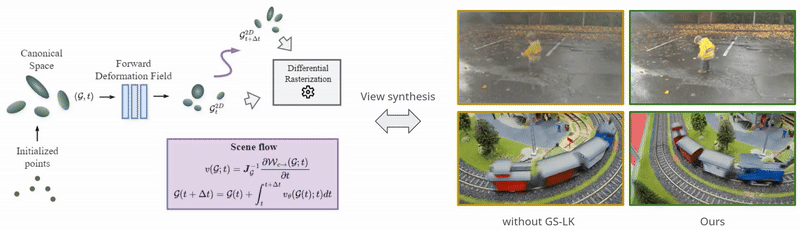
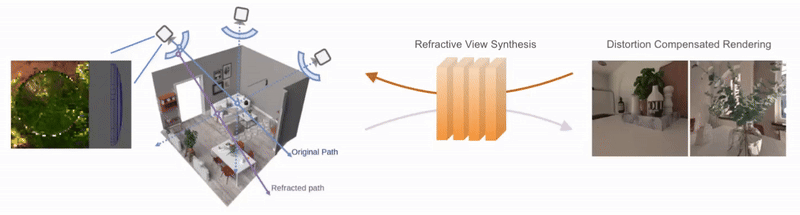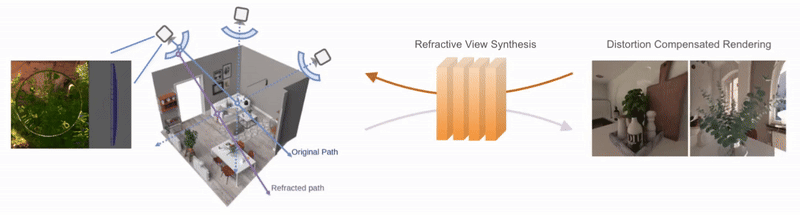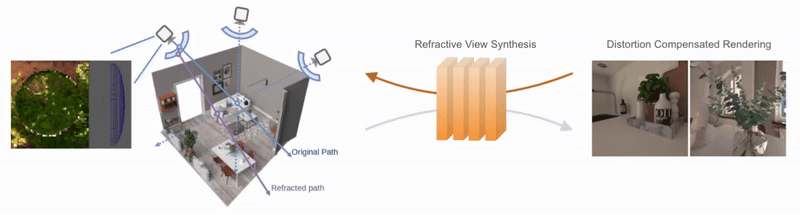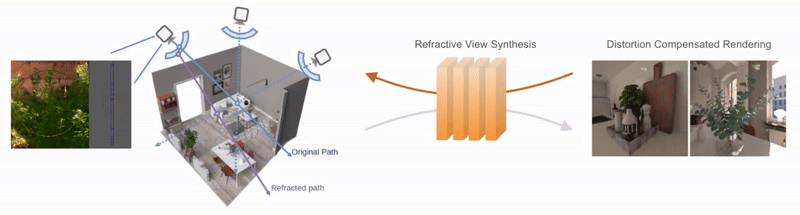
Neural Representations of Humans and Dynamic EnvironmentsThis project aims to develop advanced neural representations for humans and dynamic environments using Neural Radiance Fields (NeRF) and Light Field Networks. Objectives include enhancing spatial-temporal consistency in dynamic environments, improving human body and face modelling, integrating these techniques for a holistic model, and devising efficient algorithms for real-time rendering. The project confronts challenges in data acquisition, consistency, and real-world scalability, with anticipated applications in VR/AR, affective computing. Project: Gaussian Splatting Lucas-Kanade (ICLR 2025) Project: Through the Curved Cover: Synthesizing Cover Aberrated Scenes with Refractive Field (WACV 2025) Project: GHOST: Grounded Human Motion Generation with Open Vocabulary Scene-and-Text Contexts (WACV 2025) Project: CoGS: Controllable Gaussian Splatting (CVPR 2024) Project: Flow supervised NeRF (CVPR 2023) Project: Dynamic Lightfield Networks (CVPR 2023) Project: Controllable Neural Face Avatars (FG 2023)
|
Efficient Video TransformersThis project introduces Run-Length Tokenization (RLT), an efficient technique that accelerates video transformers by removing redundant input tokens upfront. RLT consolidates repeated tokens into a single representative token with positional encoding, ensuring minimal computational overhead and eliminating dataset-specific tuning. The approach boosts throughput by about 40% on action recognition tasks, with negligible accuracy loss, and significantly reduces fine-tuning time by over 40%. In video-language tasks, RLT maintains baseline performance while achieving a 30% reduction in training time and token count, and for longer videos, token reduction reaches up to 80%, highlighting its scalability. Project: Faster Video Transformers with Run-Length Tokenization (NeurIPS 2024)
|
Towards Photorealistic 4D Scene GenerationExisting dynamic scene generation methods mostly rely on distilling knowledge from pre-trained 3D generative models, which are typically fine-tuned on synthetic object datasets. As a result, the generated scenes are often object-centric and lack photorealism. To address these limitations, we introduce a novel pipeline designed for photorealistic text-to-4D scene generation, discarding the dependency on multi-view generative models and instead fully utilizing video generative models trained on diverse real-world datasets. Our method begins by generating a reference video using the video generation model. We then learn the canonical 3D representation of the video using a freeze-time video, delicately generated from the reference video. To handle inconsistencies in the freeze-time video, we jointly learn a per-frame deformation to model these imperfections. We then learn the temporal deformation based on the canonical representation to capture dynamic interactions in the reference video. The pipeline facilitates the generation of dynamic scenes with enhanced photorealism and structural integrity, viewable from multiple perspectives, thereby setting a new standard in 4D scene generation. Project: 4Real Towards Photorealistic 4D Scene Generation via Video Diffusion Models (NeurIPS 2024)
|
Long-term Video UnderstandingThis project aims answer zero-shot questions about videos by generating short procedural programs that derive a final answer from solving a sequence of visual subtasks. We present Procedural Video Query (ProViQ), which uses a large language model to generate such programs from an input question and an API of visual modules in the prompt, then executes them to obtain the output. Recent similar procedural approaches have proven successful for image question answering, but videos remain challenging: we provide ProViQ with modules intended for video understanding, allowing it to generalize to a wide variety of videos. This code generation framework additionally enables ProViQ to perform other video tasks in addition to question answering, such as multi-object tracking or basic video editing. ProViQ achieves state-of-the-art results on a diverse range of benchmarks, with improvements of up to 25% on short, long, open-ended, and multimodal video question-answering datasets. Project: Zero-Shot Video Question Answering with Procedural Programs (ECCV 2024)
|
Multi-person, multi-view, markerless pose estimationExisting volumetric methods for predicting 3D human pose estimation are accurate, but computationally expensive and optimized for single time-step prediction. We present TEMPO, an efficient multi-view pose estimation model that learns a robust spatiotemporal representation, improving pose accuracy while also tracking and forecasting human pose. We significantly reduce computation compared to the state-of-the-art by recurrently computing per-person 2D pose features, fusing both spatial and temporal information into a single representation. In doing so, our model is able to use spatiotemporal context to predict more accurate human poses without sacrificing efficiency. We further use this representation to track human poses over time as well as predict future poses. Finally, we demonstrate that our model is able to generalize across datasets without scene-specific fine-tuning. TEMPO achieves 10% better MPJPE with a 33x improvement in FPS compared to TesseTrack on the challenging CMU Panoptic Studio dataset. Project: TEMPO: Efficient Multi-View Pose Estimation, Tracking, and Forecasting (ICCV 2023)
|
Panoptic Studio in-the-WildMulti-view triangulation is the gold standard for 3D reconstruction from 2D correspondences given known calibration and sufficient views. However in practice, expensive multi-view setups - involving tens sometimes hundreds of cameras - are required in order to obtain the high fidelity 3D reconstructions necessary for many modern applications. By leveraging recent advances in 2D-3D lifting using neural shape priors while also enforcing multi-view equivariance, we show comparable fidelity to expensive calibrated multi-view rigs using a limited (2-3) number of uncalibrated camera views. Project: 3D Lifting Foundation Model (CVPR 2024) Project: MBW: Multiview-bootstrapping in the Wild (NeurIPS 2022) Project: High Fidelity 3D Reconstructions with Limited Physical Views (3DV 2021)
|
Automated Facial Affect Recognition guided Deep Brain StimulationWe built a platform capable of recording signals and delivering electrical stimulation to the brain to treat OCD, both in the clinic and at home environment. One exciting aspect of this platform is time-locking automatic computervision-based facial affect measurements (FACS) to deep brain stimulation (DBS), to provide objective, quantifiable, repeatable, and efficient biomarkers of treatment response to DBS.
|
Dense 3D Face AlignmentReal-time, dense 3D face alignment is a challenging problem for computer vision. To afford real-time, person-independent 3D registration from 2D video, we developed a 3D cascade regression approach in which facial landmarks remain invariant across pose over a range of approximately 60 degrees. From a single 2D image of a person’s face, a dense 3D shape is registered in real time for each frame. Project: ZFace
|
Dense Body PoseLow-resolution 3D human shape and pose estimation is a challenging problem. We propose a resolution-aware neural network which can deal with different resolution images with a single model. For training the network, we propose a directional self-supervision loss which can exploit the output consistency across different resolutions to remedy the issue of lacking high-quality 3D labels. In addition, we introduce a contrastive feature loss which is more effective than MSE for measuring high-dimensional vectors and helps learn better feature representations. Project: Low-resolution dense pose estimation
|
Cognitive Assistant for the Visually ImpairedWe developed a prototype mobile vision system for the visually impaired that performs both person and emotion recognition in diverse environments. Project: ZFace TED Talk: How New Technology Helps Blind People Explore the World
|
Automated Facial Action Unit CodingThis study addressed how design choices influence performance in facial AU coding using deep learning systems, by evaluating the combinations of different components and their parameters present in such systems.
|
Facial Expression SynthesisThis study proposed a generative approach that achieves 3D geometry based AU manipulation with idiosyncratic loss to synthesize facial expressions. With the semantic resampling, this approach provides a balanced distribution of AU intensity labels, which is crucial to train AU intensity estimators. We have shown that using the balanced synthetic set for training performs better than using the real training dataset on the same test set. The method generalizes to non-frontal views and to unseen domains.
|
Smartphone-based physiology measurements
|